|
If you find errors or omissions in this document, please don’t hesitate to contact us support@d2d.work. |
1. Overview
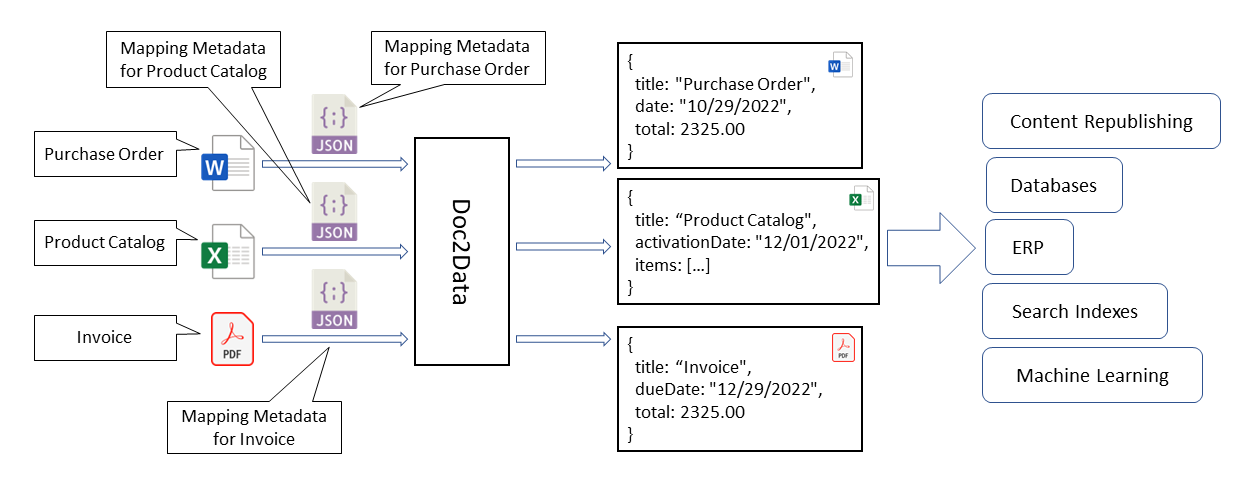
Doc2Data is a no-code data extraction solution for Structured Machine-Readable Documents (SMRD).
With the help of Doc2Data, you will quickly extract the required information from the document (or series of similar documents) and use the data in the downstream processing.
The rules for data extraction are defined via Mapping Metadata (see the Document Mapping Metadata section).
Doc2Data can be used as:
-
a Web Application providing an HTTP API. You can choose between two options:
-
self-managed microservice (Spring Boot executable jar or Docker image distribution): Install, administer, and maintain your own Doc2Data instance on-premises or in the cloud.
-
d2d.work SaaS (contact support@d2d.work to check availability): Hosted, managed, and administered by d2d.work.
-
-
an independent Console Application
-
a Java Library integrated into your JVM application.
2. Getting Started
If you are new to Doc2Data, start by reading this section. It answers the fundamental questions: "what?", "how?" and "why?".
Here is a very basic description of what Doc2Data is doing - Doc2Data extracts the required data from the document and turns it into JSON structure of your choice.
Like with any other technology, the easiest way to understand how Doc2Data works is to learn it by example.
Start with downloading the sample document.
From the Usage chapter you will learn that there are several options how you can use Doc2Data for data extraction. Here we will focus on the Document Mapping Editor as it allows us to explain the key concepts of Doc2Data using visual examples.
To see Doc2Data in action, follow the steps described below:
-
Click the link to open the Document Mapping Editor in your browser.
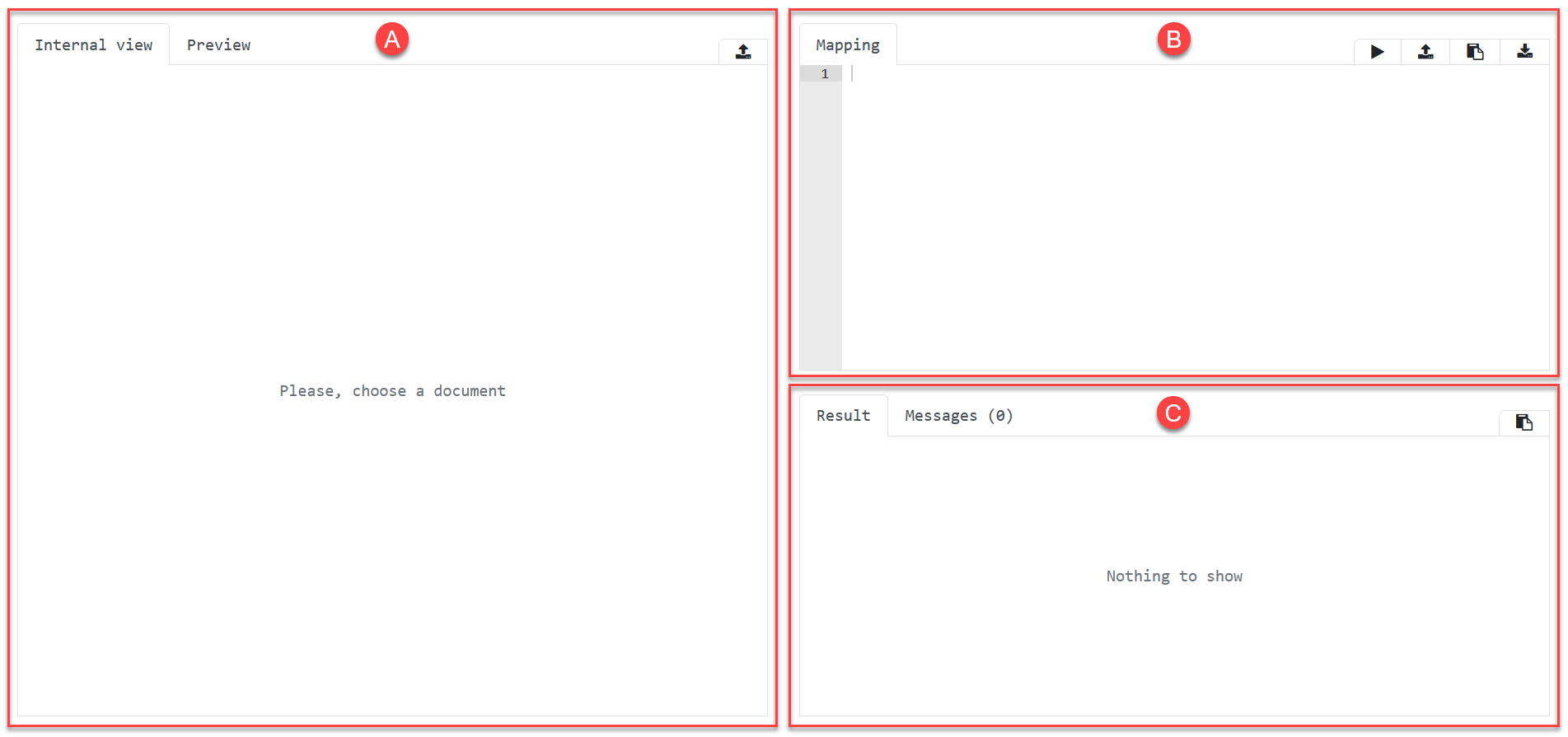 The editor is divided into three sections:
The editor is divided into three sections:-
Document - this section is used for the source document from which the data should be extracted.
-
Mapping - here you define the rules for data extraction.
-
Result - this where you find the extracted data.
-
-
Upload the source document (purchase_order.docx) in the Document section. Click the Upload icon in the top right corner of the section.
-
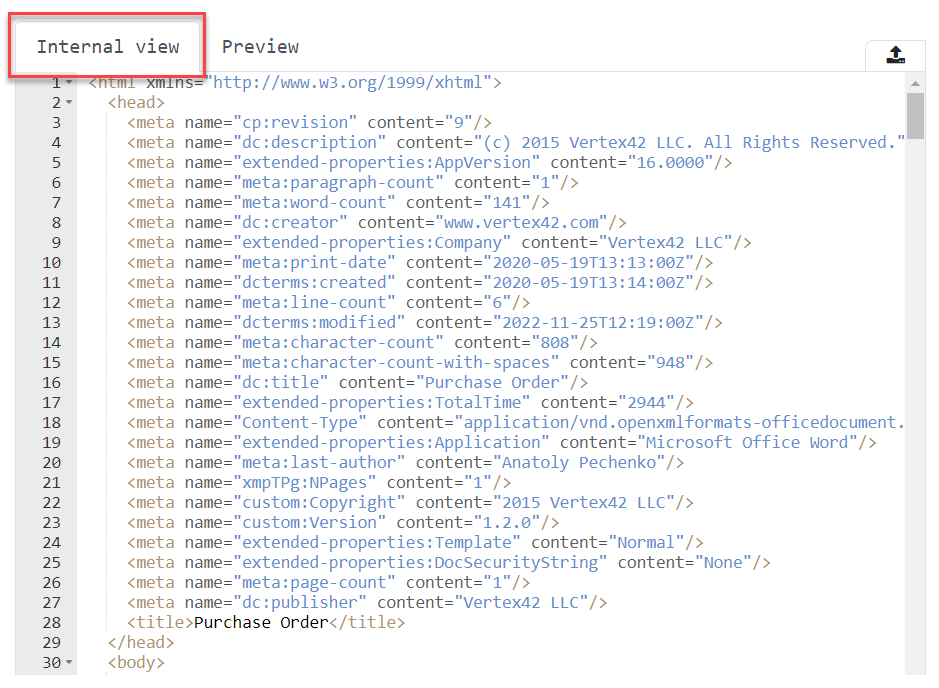
Once the document is uploaded, the system creates its internal representation in XHTML format and displays it on the Internal view tab. For more details about this step see the Product Features chapter.
-
Additionally, the system generates a dummy mapping metadata which is displayed in the Mapping section of the editor. Note that this step is optional as in real life you don’t have to generate new mapping metadata per document. Read more about the concept of mapping metadata in the Document Mapping Metadata chapter.
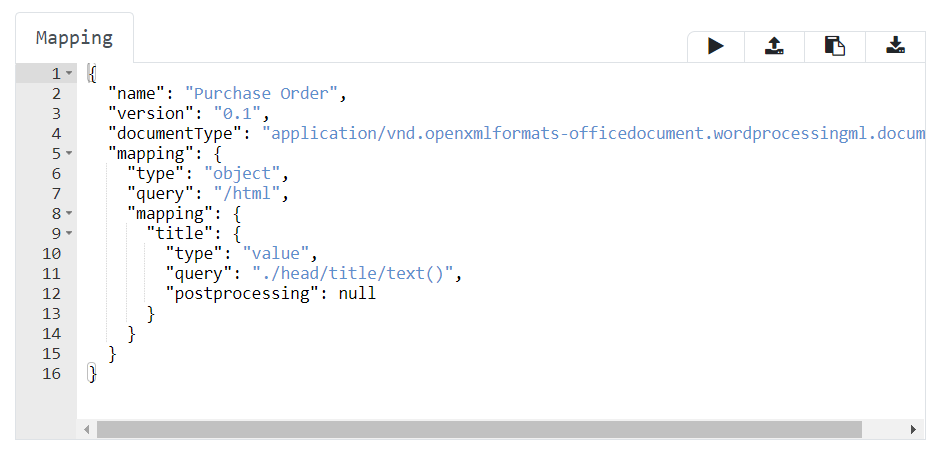
-
Modify the mapping to extract more valuable information, for example, purchase order amount. Insert the following snippet after the line 13.
"amount": { "type": "value", "query": "./body/table/tbody/tr/td[preceding-sibling::td[p/b='TOTAL']]/p/b/text()" }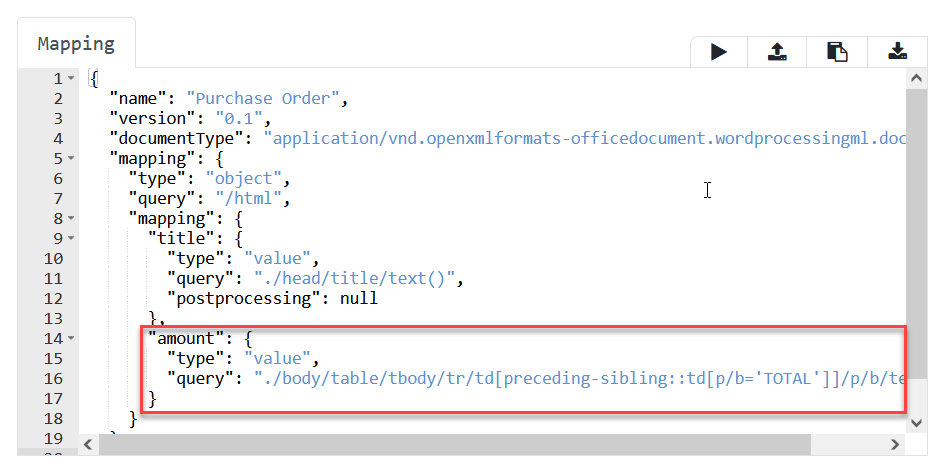
-
Now everything is ready to process the document with the mapping metadata. To do this click Execute icon in the toolbar on top of the Mapping section.
-
The system applies mapping metadata to the internal representation of the document and returns extracted data as JSON. This information is displayed in the Result section of the editor.
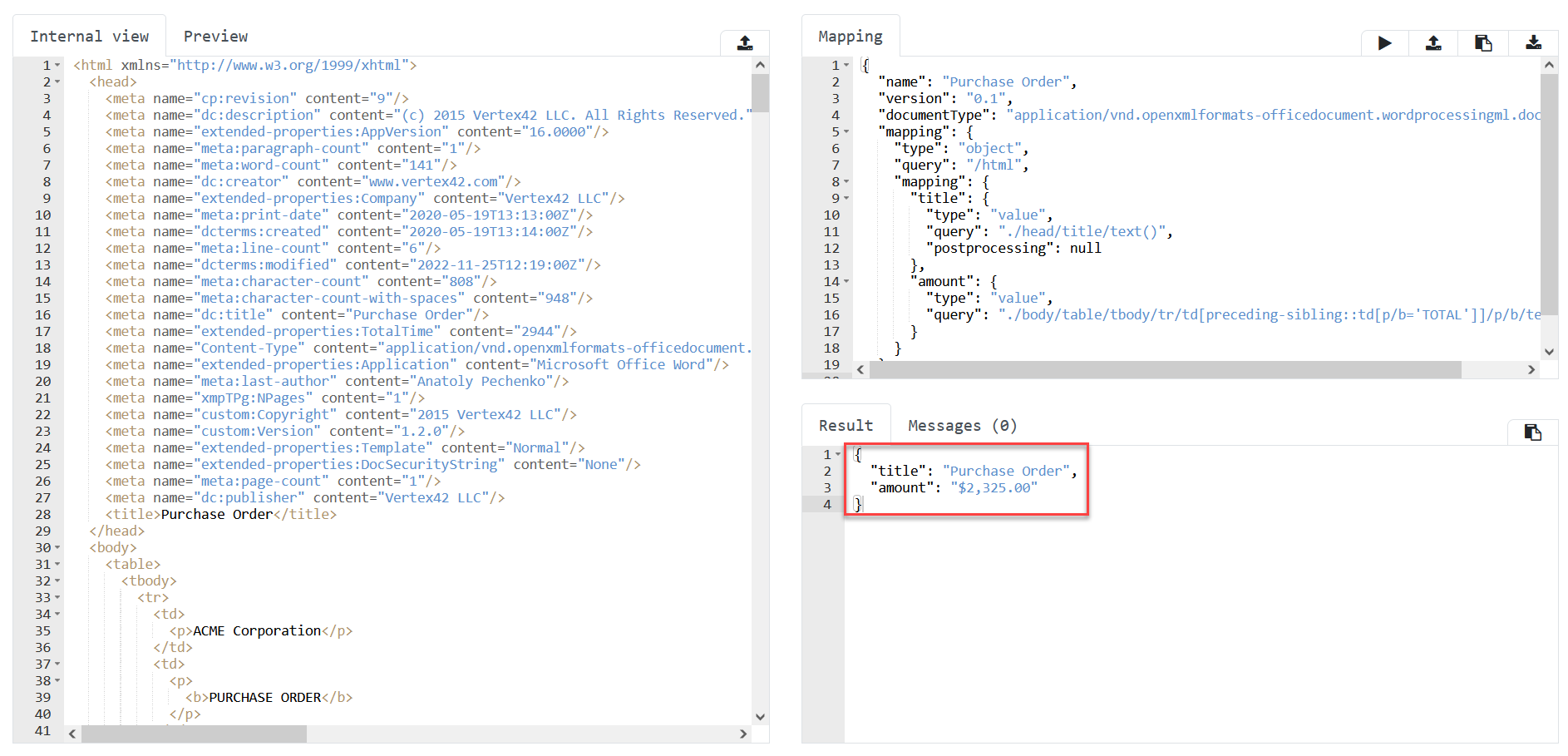
Let’s analyze this result with a closer look on the mapping metadata that was used to receive it:
{
"name": "Purchase Order",
"version": "0.1",
"documentType": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"mapping": {
"type": "object", (1)
"query": "/html",
"mapping": {
"title": { (2)
"type": "value",
"query": "./head/title/text()", (3)
"postprocessing": null
},
"amount": {
"type": "value",
"query": "./body/table/tbody/tr/td[preceding-sibling::td[p/b='TOTAL']]/p/b/text()"
}
}
}
}| 1 | "type" - here it is defined that the result should be an object. But it
can be also an array of objects or strings (other types are not supported yet). |
| 2 | "title" - the name of the property in the result object. |
| 3 | "query" - XPath expression used to retrieve the value from XHTML
representation of the document. |
You can find more examples for the advanced cases in the chapter Document Mapping Metadata.
3. Product Features
This section dives into the details of Doc2Data, explaining the key concepts of the product.
The core of the Doc2Data project is mapping. The idea behind the data extraction is simple enough. We are trying to convert any document into our internal representation (XHTML) and then apply mapping to the internal model. We are calling it mapping because, in reality, we are doing mapping of the source segment into the part of the target structure, instead of data extraction.
Users can define the mapping process using mapping metadata (see the details in the section below).
In general, the mapping metadata is a simple JSON file with the definitions for mapping. Alternatively, you can use Java API to build the mapping metadata object.
3.1. Document Mapping Metadata
The metadata object itself contains information about mapping, e.g., name, version, and document type. Also, it has instructions for mapping of the root segment.
Here is a basic example and the starting point for your journey with the Doc2Data solution.
JSON
{
"name": "Sample Mapping", (1)
"version": "0.1", (2)
"documentType": "application/pdf", (3)
"mapping": { (4)
"type": "object",
"query": "/html/body",
"mapping": {
"someProperty": {
"type": "value",
"query": "./text()"
}
}
}
}Java
DocumentMappingMetadata.builder()
.name("Sample Mapping") (1)
.version(DocumentMappingVersion.VERSION_0_1) (2)
.documentType(DocumentType.APPLICATION_PDF) (3)
.mapping( (4)
ObjectSegmentMapping
.builder()
.query("/html/body")
.map("someProperty",
ValueSegmentMapping
.builder()
.query("./text()")
.build())
.build())
.build();| 1 | name - is mapping name |
| 2 | version - internal mapping format version |
| 3 | documentType - type of the input file, see information about supported document types |
| 4 | mapping - instructions about how to map the root segment, see Document Segment Mapping |
3.1.1. Document Types
As mentioned above, we are converting the input document to the internal format (XHTML). This operation brings some limitations to the document types we are currently supporting. For now, the system supports only Word, Excel and PDF documents.
You can use only following values for the documentType property:
-
application/vnd.openxmlformats-officedocument.wordprocessingml.document- for Word documents -
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet- for Excel documents -
application/pdf- for PDF documents.
3.1.2. Document Segment Mapping
While talking about segment mapping, it is good to start with the definition of the segment itself.
Well, we are using XHTML as an internal representation of the input document. You can split any text document into fragments (symbols, lines, paragraphs). It is even easier to do with the XML documents. By segment we mean part of the XHTML document, which you can identify (select) via the XPath query. Currently, we are supporting only XPath. This implies that we are selecting segments using XPath syntax. In the future, we might use Regex, which allows us to use text as an internal representation of the document.
You can find basic XPath syntax here.
The segment can be mapped to the output structure in four different ways:
-
As a single value (String) for corresponding property in the result object (Value Segment Mapping).
-
As a constant value (String) for corresponding property in the result object (Constant Segment Mapping).
-
As an array (Array) of values for corresponding property in the result object (Array Segment Mapping).
-
As an object (Map) for corresponding property in the result object (Object Segment Mapping).
Array and Object provide the possibility to have nested mappings of any type.
We also have a special type of mapping (Constant Segment Mapping) which actually does not use source segment, but writes value directly into the output structure.
Value Segment Mapping
Value mapping type should be used in case you need to map a single simple value.
In the example below we extract a company name from the Purchase Order.
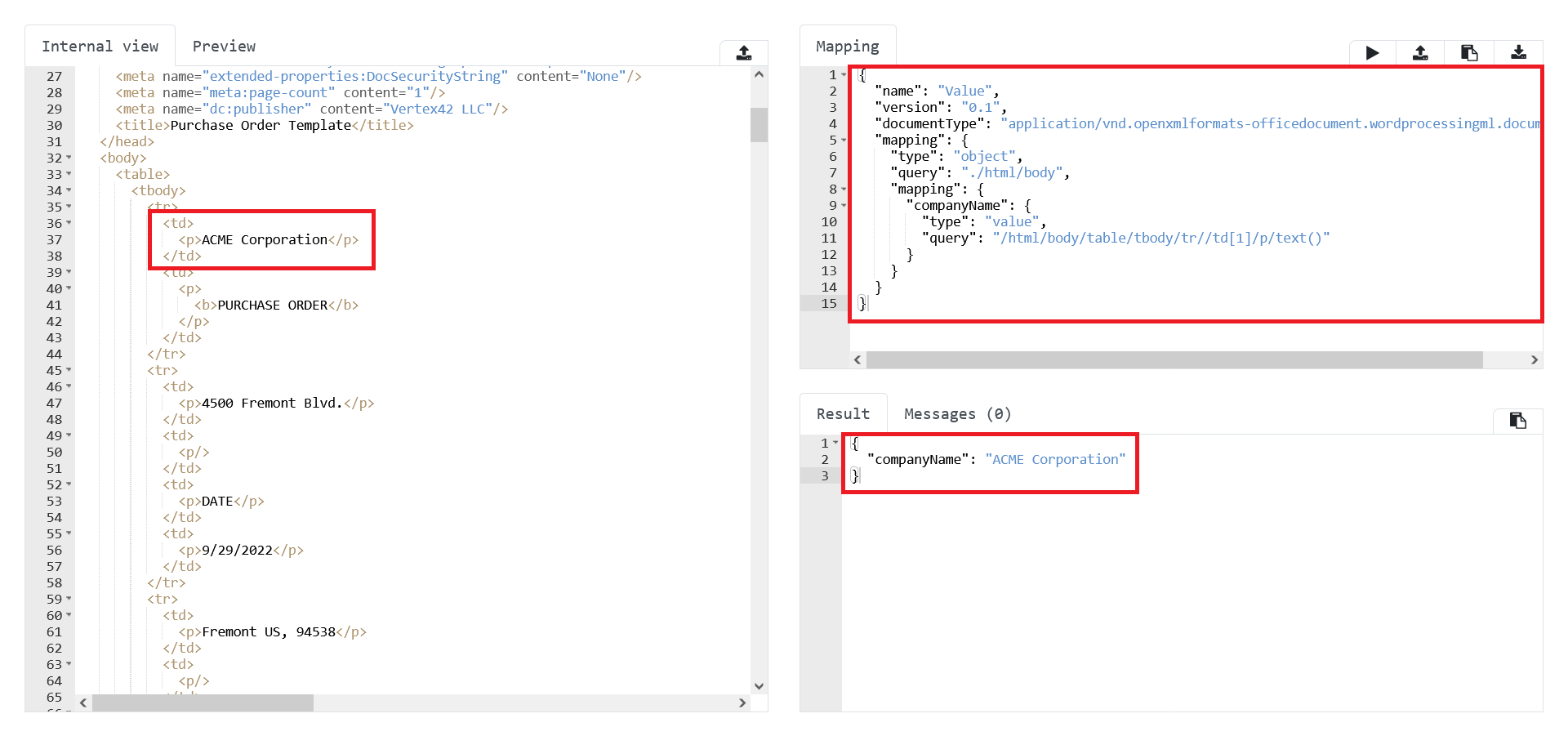
In this case mapping would be:
{
"name": "Value",
"version": "0.1",
"documentType": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"mapping": {
"type": "object",
"query": "./html/body",
"mapping": {
"companyName": { (1)
"type": "value", (2)
"query": "/html/body/table/tbody/tr//td[1]/p/text()" (3)
}
}
}
}| 1 | companyName - the name of property in the result object, in the example
above the result object will be { "companyName": "ACME Corporation"}. |
| 2 | type - the type of the segment mapping, here the value is value,
the array, object and constant are also valid values |
| 3 | query - the XPath query for segment selection |
Post Processing
For every value to be extracted, you can also set post-processing rules using
regular expressions.
Only the values that comply with the specified pattern will be extracted.
For example, the following rule will extract number values only:
{
"name": "Value",
"version": "0.1",
"documentType": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"mapping": {
"type": "object",
"query": "./html/body",
"mapping": {
"companyName": {
"type": "value",
"query": "/html/body/table/tbody/tr//td[1]/p/text()",
"postprocessing": {
"type": "regex", (1)
"regex": "([^\\s]+)" (2)
}
}
}
}
}| 1 | type - the type of the postprocessing, currently only regex is
supported. |
| 2 | regex - the actual regular expression which will be applied to the value
returned by XPath selector. In current example the original result
is ACME Corporation, but after post-processing we will have ACME only. |
Array Segment Mapping
Array Mapping type should be used in case you need to map a collection of segments into a collection of nested types.
In the example below we extract a collection of headers from xlsx.
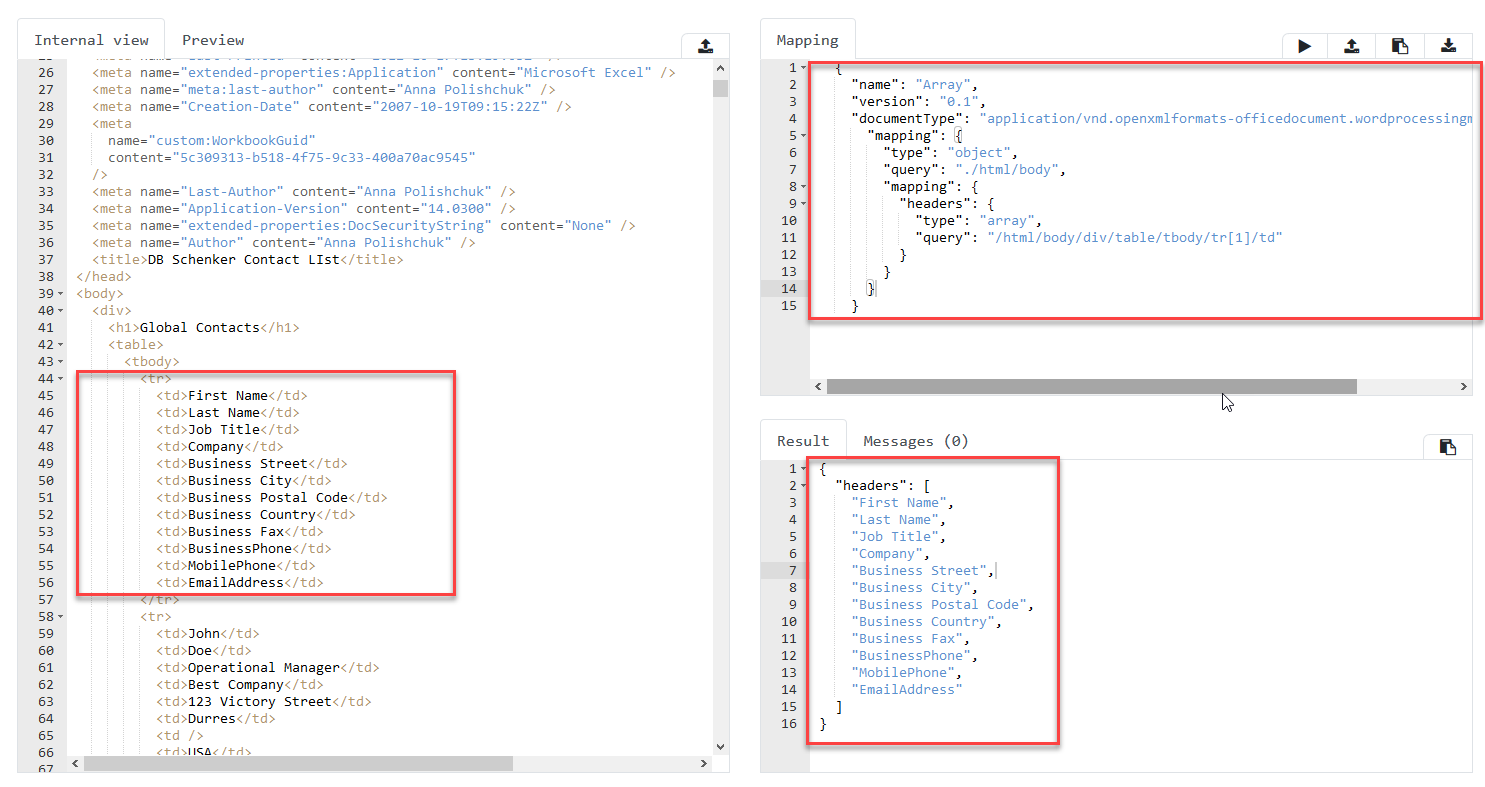
In this case mapping would be:
{
"name": "Array",
"version": "0.1",
"documentType": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"mapping": {
"type": "object",
"query": "/html/body",
"mapping": {
"headers": {
"type": "array",
"query": "./div/table/tbody/tr[1]/td",
"mapping": {
"type": "value",
"query": "./text()"
}
}
}
}
}In case of array mapping, query will select nodes for result array, and
nested mapping will define how to map/process items of the array.
The nested mapping, in this case, could be of type value only.
You might omit the query parameter in the nested value mapping.
We will use text representation of the array segment in that case.
Even more, you can skip the whole nested value mapping.
We will create a transient instance of the value mapping with the segments'
default text representation.
Object Segment Mapping
Object mapping type should be used in case you need to map a set of values for the same object.
The object mapping allows you not only to combine properties into one object, but build structures with the nested mappings.
In case we map an object, we first need to set the XPath to the place where the object is located, and then set the mapping for each of its parts (relative to the object location).
In the example below we map a company’s address object into separate Street and Building values.
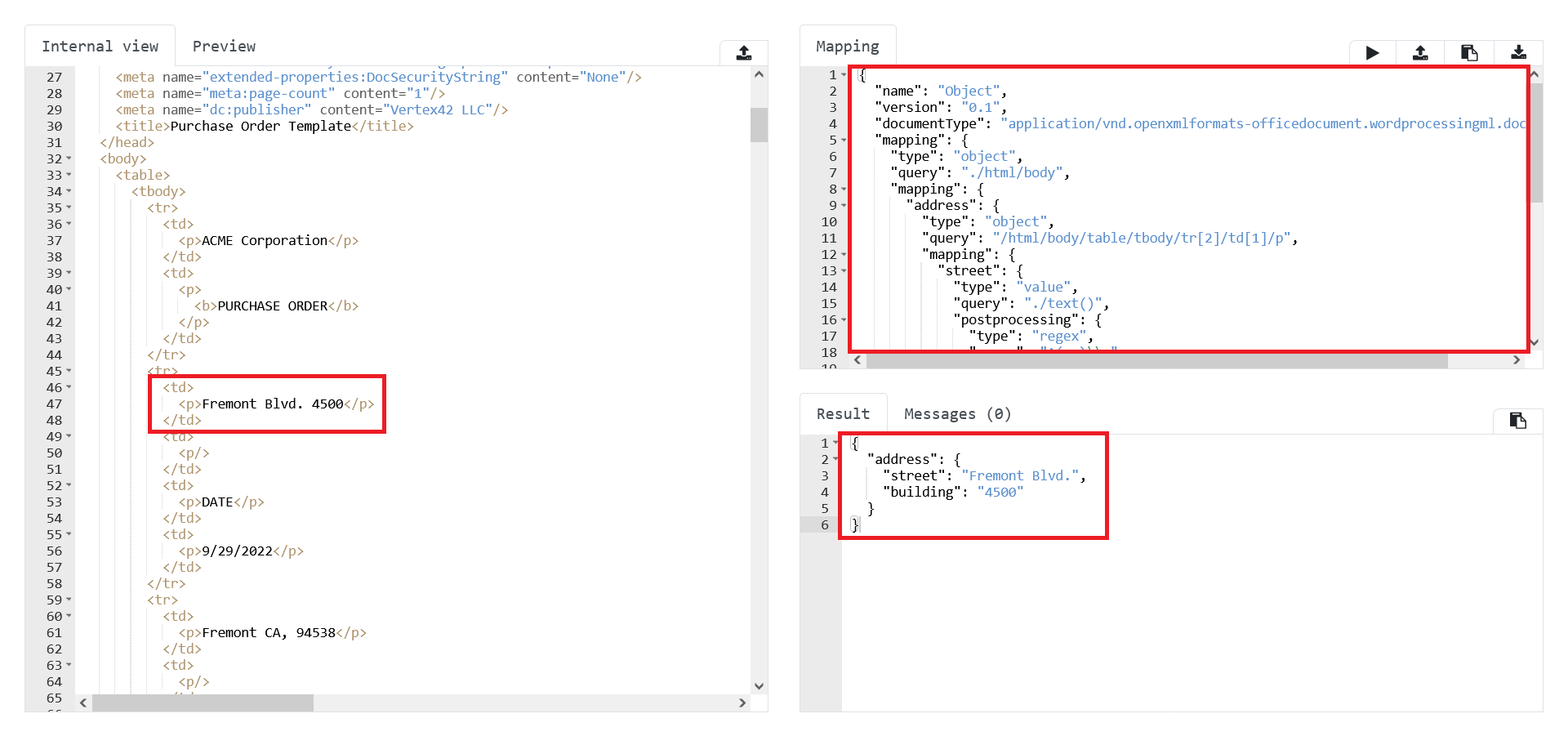
In this case, the mapping would be:
{
"name": "Object",
"version": "0.1",
"documentType": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"mapping": {
"type": "object",
"query": "./html/body",
"mapping": { (1)
"address": {
"type": "object",
"query": "/html/body/table/tbody/tr[2]/td[1]/p",
"mapping": { (1)
"street": {
"type": "value",
"query": "./text()",
"postprocessing": {
"type": "regex",
"regex": "^(.+)\\s"
}
},
"building": {
"type": "value",
"query": "./text()",
"postprocessing": {
"type": "regex",
"regex": "^.+\\s(.+)$"
}
}
}
}
}
}
}| 1 | mapping - the collection of nested mappings for the parent mapping. There
is no limit for the levels of hierarchy. |
Constant Segment Mapping
Constant mapping type should be used in case you do not have source segment in the document, but you need constant value in right place of the output structure.
Sometimes not all information present in the source document, but it is known by the person who is creating the mapping and it is constant.
In the example below we fill in a company type with the LLC value as far
as we know that all companies in similar documents will have the same type.
In this case mapping would be:
{
"name": "Value",
"version": "0.1",
"documentType": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"mapping": {
"type": "object",
"query": "./html/body",
"mapping": {
"companyName": {
"type": "value",
"query": "/html/body/table/tbody/tr//td[1]/p/text()"
},
"companyType": { (1)
"type": "constant", (2)
"value": "LLC" (3)
}
}
}
}| 1 | companyType - the name of property in the result object, in the example
above the result object will be { "companyType": "LLC" }. |
| 2 | type - the type of the segment mapping, here the value is constant |
| 3 | value - the value which will be used as result of the mapping |
3.1.3. Document Mapping Errors
The Document Mapping process consists of two parts: parsing and mapping. Similar to other methods here, something could go not as the user expects. The application tries to be user-friendly and warn the user about errors as early as possible.
The errors could appear on one of three steps:
-
While parsing the Document Mapping Metadata
-
While parsing the Document
-
While applying the Document Mapping to the internal representation of the Document
Document Mapping Metadata parsing errors
- Error
-
Unable to parse document mapping metadata
- Reasons
-
-
The content is not accessible for reading.
-
The content is not valid document mapping metadata.
-
Document parsing errors
- Error
-
Unable to parse Document
- Reasons
-
-
The content is not accessible for reading.
-
The parser unable to convert the Document into the internal format.
-
Document mapping errors
- Error
-
Validation errors
- Reasons
-
-
The detected document type does not correspond to the type defined in the mapping.
-
- Error
-
Unable to map document segment
- Reasons
-
-
The segment selection failed due to XPath compilation/evaluation failure.
-
The segment post-processing failed due to Regex compilation/evaluation failure.
-
3.2. HTTP API
3.2.1. Generate Mapping
The Generate Mapping endpoint allows building simple mapping metadata based on the given document. It could be the right starting point for document processing.
Request
POST /api/document/generate-mapping-metadata HTTP/1.1
Content-Type: multipart/form-data;charset=UTF-8; boundary=6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Accept: application/json
Host: localhost:8080
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Content-Disposition: form-data; name=document; filename=purchase_order.txt
Content-Type: text/plain
ACME Corporation
DATE 9/29/2022
PO 343546
23423423 Product XYZ 15 150.00 2,250.00
45645645 Product ABC 1 75.00 75.00
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm--Response
HTTP/1.1 200 OK
Vary: Origin
Vary: Access-Control-Request-Method
Vary: Access-Control-Request-Headers
Content-Type: application/json
Content-Length: 228
{"result":{"name":"Generated Mapping","version":"0.1","documentType":"text/plain","mapping":{"type":"object","query":"/html","mapping":{"title":{"type":"value","query":"./head/title/text()","postprocessing":null}}}},"errors":[]}3.2.2. Process Document
The Process Document endpoint allows using the document processing flow: transform and process the document to extract the valuable information into a JSON like data structure.
Request
POST /api/document/process HTTP/1.1
Content-Type: multipart/form-data;charset=UTF-8; boundary=6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Accept: application/json
Host: localhost:8080
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Content-Disposition: form-data; name=document; filename=purchase_order.txt
Content-Type: text/plain
ACME Corporation
DATE 9/29/2022
PO 343546
23423423 Product XYZ 15 150.00 2,250.00
45645645 Product ABC 1 75.00 75.00
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Content-Disposition: form-data; name=metadata; filename=purchase_order_meta.json
Content-Type: application/json
{
"name": "ACME Corporation Purchase Order",
"version": "0.1",
"documentType": "text/plain",
"mapping": {
"type": "object",
"query": "./html/body",
"mapping": {
"company_name": {
"type": "value",
"query": "./p[1]",
"postprocessing": {
"type": "regex",
"regex": "^(.*)(?=\n)"
}
}
}
}
}
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm--3.2.3. Transform Document
The Transform Document endpoint allows splitting the document processing flow into independent phases to provide better scalability. It accepts documents and returns their internal representation (XHTML). You have to use the endpoint together with the Process XML endpoint.
Request
POST /api/document/transform HTTP/1.1
Content-Type: multipart/form-data;charset=UTF-8; boundary=6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Accept: application/json
Host: localhost:8080
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Content-Disposition: form-data; name=document; filename=purchase_order.txt
Content-Type: text/plain
ACME Corporation
DATE 9/29/2022
PO 343546
23423423 Product XYZ 15 150.00 2,250.00
45645645 Product ABC 1 75.00 75.00
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm--Response
HTTP/1.1 200 OK
Vary: Origin
Vary: Access-Control-Request-Method
Vary: Access-Control-Request-Headers
Content-Type: application/json
Content-Length: 417
{"result":"<html xmlns=\"http://www.w3.org/1999/xhtml\">\n <head>\n <meta name=\"Content-Encoding\" content=\"ISO-8859-1\"/>\n <meta name=\"Content-Type\" content=\"text/plain; charset=ISO-8859-1\"/>\n <title/>\n </head>\n <body>\n <p>ACME Corporation\n\nDATE 9/29/2022\nPO 343546\n\n23423423 Product XYZ 15 150.00 2,250.00\n45645645 Product ABC 1 75.00 75.00\n</p>\n </body>\n</html>\n","errors":[]}3.2.4. Process XML
The Process XML endpoint allows processing the document’s internal representation (XHTML) or arbitrary XML with mapping metadata to extract the valuable information into a JSON like data structure.
Request
POST /api/xml/process HTTP/1.1
Content-Type: multipart/form-data;charset=UTF-8; boundary=6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Accept: application/json
Host: localhost:8080
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Content-Disposition: form-data; name=document; filename=purchase_order.xhtml
Content-Type: text/plain
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="Content-Encoding" content="ISO-8859-1"/>
<meta name="Content-Type" content="text/plain; charset=ISO-8859-1"/>
<title/>
</head>
<body>
<p>ACME Corporation
DATE 9/29/2022
PO 343546
23423423 Product XYZ 15 150.00 2,250.00
45645645 Product ABC 1 75.00 75.00
</p>
</body>
</html>
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm
Content-Disposition: form-data; name=metadata; filename=purchase_order_meta.json
Content-Type: application/json
{
"name": "ACME Corporation Purchase Order",
"version": "0.1",
"documentType": "text/plain",
"mapping": {
"type": "object",
"query": "./html/body",
"mapping": {
"company_name": {
"type": "value",
"query": "./p[1]",
"postprocessing": {
"type": "regex",
"regex": "^(.*)(?=\n)"
}
}
}
}
}
--6o2knFse3p53ty9dmcQvWAIx1zInP11uCfbm--4. Usage
4.1. System Requirements
Java version 17.
Please, note that we use Azul Zulu OpenJDK for development and in our Docker image, so this vendor is recommended for running an application. Other vendors can be used without any warranty.
4.2. Web Application
The main purpose of Doc2Data web application is to provide an HTTP API. Additionally, it comes with a Document Mapping Editor (DME) which can be used to create and test mappings in browser.
There are two options for the distribution of Doc2Data web application.
4.2.1. Spring Boot Executable JAR
Use java -jar to run Spring Boot’s executable jar file.
$ java -jar dtd-webapp-1.0.0-m7.jar
4.2.2. Docker Image
An alternative way of having web application available is using docker image.
$ docker run doc2data:latest
4.2.3. SaaS Platform
If you don’t want to manage your own instance of Doc2Data, use Doc2Data SaaS platform. Please, note that Doc2Data processes your documents without storing them on our servers.
To test HTTP API provided by Doc2Data, you can:
-
use Swagger UI
-
download OpenAPI specification
-
download Postman collection.
4.3. Console Application
Our console application is just executable jar file. Once downloaded,
use java -jar with the .jar file.
$ java -jar dtd-cli-1.0.0-m7.jar
This command will show you helper information about available actions.
The following command will do the same:
$ java -jar dtd-cli-1.0.0-m7.jar help
So, basically you are able to perform three main actions with the console application:
You may also use help for any command to display detailed usage information.
Note that actual result of every command is wrapped into JSON object and stored in the field "result".
$ java -jar dtd-cli-1.0.0-m7.jar help <COMMAND>
4.3.1. Generate Mapping
This command is a good starting point if you don’t know where to start your journey with the Doc2Data solution.
$ java -jar dtd-cli-1.0.0-m7.jar generate-mapping-metadata <document-file> (1)
Short version of the command also available:
$ java -jar dtd-cli-1.0.0-m7.jar generate [<document-file>] (1)
| 1 | - the file here is the path to the document file you will process/map. |
As a result, the application will generate sample mapping based on your input.
4.3.2. Transform Document
The document’s mapping process relies on an internal document view (XHTML) by applying various XPath expressions.
That is why it is required to know the document’s internal view to create valid XPath expression.
The transform command will do what you need.
$ java -jar dtd-cli-1.0.0-m7.jar transform-document [<document-file>]
Short version:
$ java -jar dtd-cli-1.0.0-m7.jar transform [<document-file>]
The output from the command will be an XHTML representation of the given document.
4.3.3. Process Document
Finally, the process command does actual document processing/mapping according
to the specified mapping metadata and outputs results as JSON into the console.
$ java -jar dtd-cli-1.0.0-m7.jar process-document -m=<metadata-file> [<document-file>]
Short version:
$ java -jar dtd-cli-1.0.0-m7.jar process -m=<metadata-file> [<document-file>]
4.4. Java Library
In this section we will guide you on how to use the Doc2Data solution from your JVM based application. Also, we will show how to create your first mapping with using Java API.
Suppose that you have JVM based application and would like to use our API in your business flow.
4.4.1. Add as External Dependency
You can add dtd-flow as an external dependency to your project.
4.4.2. Create Metadata
The best way of creating Document Mapping Metadata programmatically is the usage of the builder API.
DocumentMappingMetadata metadata = DocumentMappingMetadata.builder()
.name("Sample Mapping")
.version(DocumentMappingVersion.VERSION_0_1)
.documentType(DocumentType.APPLICATION_PDF)
.mapping(
ObjectSegmentMapping
.builder()
.query("/html/body")
.map("someProperty",
ValueSegmentMapping
.builder()
.query("./text()")
.build())
.build())
.build();Alternatively, you can build the metadata object by deserializing JSON file
with mapping metadata.
DocumentMappingMetadata metadata = null;
try (InputStream stream = Files.newInputStream(Paths.get("mapping.json"))) {
metadata = DocumentMappingMetadataSerializationFactoryProvider.getFactory(JSON).create().deserialize(stream);
} catch (IOException e) {
e.printStackTrace();
}4.4.3. Process Document
Once you have metadata object, you need to have an instance of
the work.d2d.doc2data.DocumentProcessor.
DocumentProcessor processor = new DocumentProcessor(
DocumentTransformerFactoryProvider.getFactory(DocumentTransformerFactoryProvider.XHTML).newTransformer(),
DocumentMappingProcessorFactoryProvider.getFactory(XPATH).newProcessor());
try (InputStream stream = Files.newInputStream(Paths.get("document.pdf"))) {
Result<Object> result = processor.process(stream, metadata);
if (result.isSuccess()) {
System.out.println(result.getResult());
}
} catch (IOException e) {
e.printStackTrace();
}4.4.4. Document Processing Sample
The full source code for the getting started example:
package work.d2d.doc2data.docs.processing;
import work.d2d.doc2data.DocumentProcessor;
import work.d2d.doc2data.Result;
import work.d2d.doc2data.mapping.DocumentMappingMetadata;
import work.d2d.doc2data.mapping.DocumentMappingVersion;
import work.d2d.doc2data.mapping.DocumentType;
import work.d2d.doc2data.mapping.ObjectSegmentMapping;
import work.d2d.doc2data.mapping.ValueSegmentMapping;
import work.d2d.doc2data.processing.DocumentMappingProcessorFactoryProvider;
import work.d2d.doc2data.transformation.DocumentTransformerFactoryProvider;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
import static work.d2d.doc2data.processing.DocumentMappingProcessorFactoryProvider.XPATH;
public class GettingStartedJavaLibrary {
public static void main(String[] args) {
DocumentMappingMetadata metadata = createDocumentMappingMetadata();
// tag::processor[]
DocumentProcessor processor = new DocumentProcessor(
DocumentTransformerFactoryProvider.getFactory(DocumentTransformerFactoryProvider.XHTML).newTransformer(),
DocumentMappingProcessorFactoryProvider.getFactory(XPATH).newProcessor());
try (InputStream stream = Files.newInputStream(Paths.get("document.pdf"))) {
Result<Object> result = processor.process(stream, metadata);
if (result.isSuccess()) {
System.out.println(result.getResult());
}
} catch (IOException e) {
e.printStackTrace();
}
// end::processor[]
}
protected static DocumentMappingMetadata createDocumentMappingMetadata() {
// tag::metadata[]
DocumentMappingMetadata metadata = DocumentMappingMetadata.builder()
.name("Sample Mapping")
.version(DocumentMappingVersion.VERSION_0_1)
.documentType(DocumentType.APPLICATION_PDF)
.mapping(
ObjectSegmentMapping
.builder()
.query("/html/body")
.map("someProperty",
ValueSegmentMapping
.builder()
.query("./text()")
.build())
.build())
.build();
// end::metadata[]
return metadata;
}
}5. Appendices
Appendix A: Glossary
This appendix contains list of terms, and their definitions found in the documentation relating to a specific subject.
- Document Mapping Metadata (DMM)
-
JSON file representing meta information explaining how data could be extracted and which documents it could be applicable.
- Document Mapping Editor (DME)
-
Web application for visual designing Document Mapping Metadata (DMM)